What is a knowledge layer for engineering teams? A clear guide for April 2026
Every time a PR merges, it rewrites part of your team's story. The architectural decision that made sense three months ago might be obsolete now, but the doc explaining it hasn't changed. A knowledge layer for engineering teams watches for those changes and keeps knowledge current without anyone remembering to update it. Your codebase is the source of truth, but code alone doesn't explain why decisions were made or what breaks if you change them. That context is your moat, and the teams that treat it as a managed asset are the ones building real competitive advantages.
TLDR:
- A knowledge layer connects your codebase, tools, and team context into one self-updating system
- Engineers spend 30+ minutes daily searching for answers already documented somewhere in your stack
- Knowledge graphs plus vector search let you trace dependencies and surface relevant context together
- Falconer maintains a living knowledge graph across GitHub, Slack, and docs with automatic updates
Why your AI model isn't your competitive advantage
Every major AI lab is shipping new models on what feels like a weekly cadence. And yet, most engineering teams running AI pilots are seeing underwhelming results. Why?
Because the model isn't the bottleneck. Your context is.
As Stack Overflow noted when launching Stack Internal, enterprise AI works best when it's grounded in a company's own human intelligence layer. The same frontier model is available to every competitor you have. What separates teams that ship from teams stuck in pilot purgatory is the institutional knowledge they can actually feed those models: their codebase decisions, architectural rationale, and tribal context that lives nowhere obvious.
That context is your moat. The question is whether you have a system to capture and maintain it.
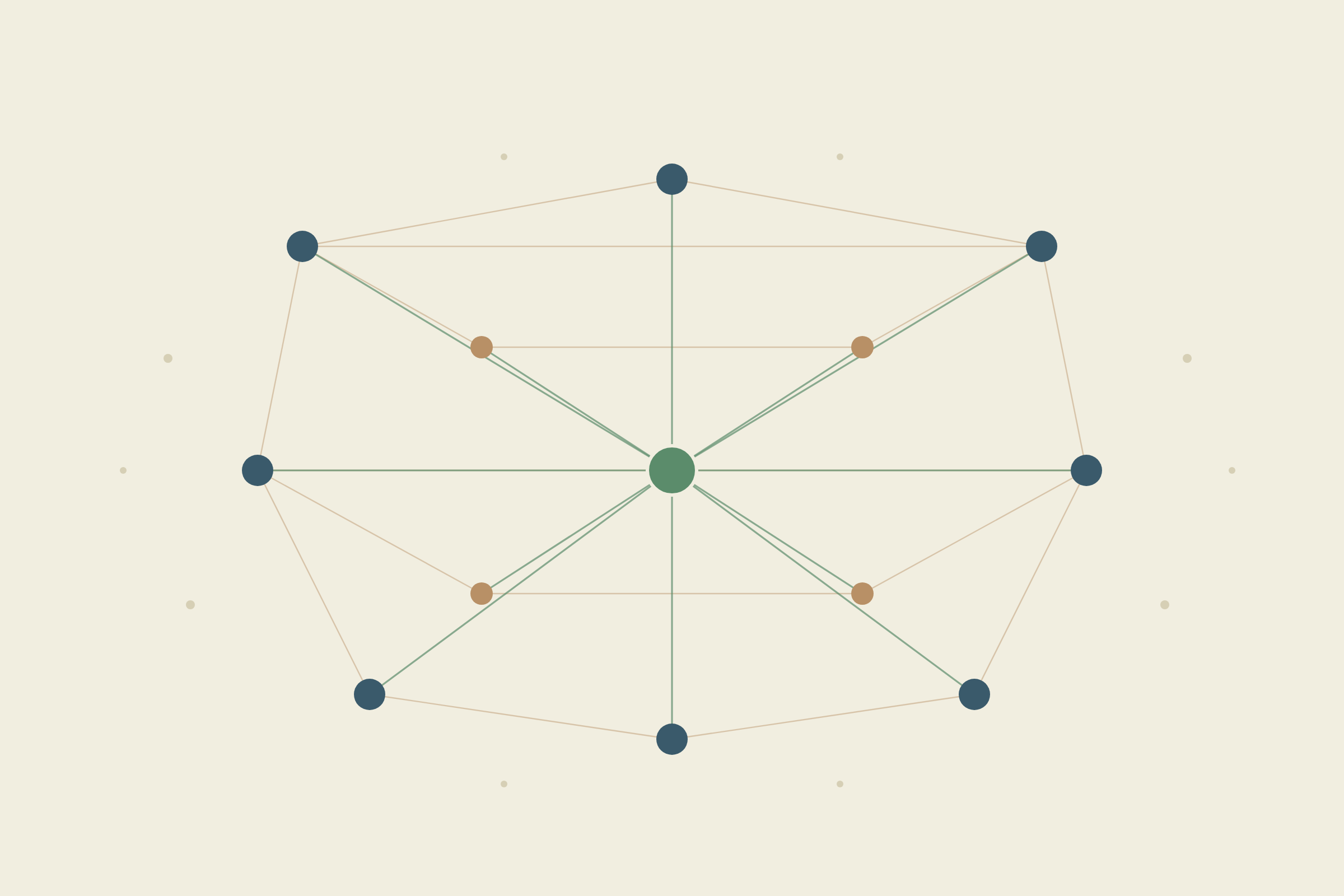
What a knowledge layer actually is (and what it's not)
A knowledge layer is the connective tissue between your codebase, your tools, and your team's collective understanding. It captures institutional knowledge from the places work actually happens (GitHub, Slack, Linear, Google Docs) and keeps that knowledge accurate as things change.
Here's what it's not: a wiki someone updates quarterly, a search tool that returns ten blue links, or a Notion workspace where docs go to quietly rot.
Traditional approaches assume someone will write the docs, keep them current, and remember where they live. That assumption falls apart the moment your team ships faster than anyone can type. A knowledge layer removes that dependency entirely. It watches for changes and keeps everything in sync without manual upkeep. The result is a shared memory that both your teammates and your AI agents can actually trust.
| Approach | Update mechanism | Context retention | AI agent integration | Best for | | --- | --- | --- | --- | --- | | Company wiki (Confluence, Notion) | Manual updates required after every code change, quarterly documentation sprints, dedicated technical writers | Knowledge decays immediately after creation, context scattered across disconnected pages, no relationship mapping between topics | Agents must search statically and often retrieve outdated information that contradicts current codebase state | Stable systems with infrequent changes, marketing and HR documentation, policy and procedure guides | | Search tools (Elasticsearch, internal search) | Indexes content as-is with no validation, returns links to potentially stale documents, requires users to verify accuracy themselves | No understanding of relationships between services or dependencies, purely keyword or semantic matching without structural knowledge | Returns ranked results but cannot synthesize answers or trace dependencies across multiple sources | Finding known documents quickly, searching large archives, keyword-based document discovery | | Code comments and READMEs | Updated only when developers remember during PR reviews, often becomes outdated within weeks of major refactors | Context lives exclusively in repository, invisible to non-engineers, no connection to tickets or design decisions made in other tools | Agents see code-level details but miss broader architectural rationale and cross-service implications | Implementation-level details, function-specific behavior, quick setup instructions for individual repositories | | Knowledge layer (Falconer) | Automatically detects code changes via repository monitoring and flags affected documentation for immediate updates | Maintains living knowledge graph connecting code, conversations, tickets, and docs with relationship mapping across all sources | Provides agents with accurate, structured context on demand through protocols like MCP so outputs match team conventions | Fast-moving engineering teams, AI agent workflows, maintaining institutional knowledge across distributed tools and repositories |
The engineering knowledge problem: when code moves faster than docs
The half-life of an engineering degree has shrunk from roughly 35 years a century ago to about 2 years today. Technical knowledge expires at a pace that makes traditional documentation feel like writing in sand at high tide.
For engineering teams, the source of truth is the codebase. When that code changes dozens of times a day across multiple repositories, any doc written about it starts decaying the moment it's saved.
Engineers bounce between GitHub, Slack, Linear, Notion, and their IDE, sometimes within a single task. Knowledge fragments scatter across all of them. The onboarding doc lives in one place, the architectural decision record in another, and the real explanation for why the service was built that way? Buried in a Slack thread from four months ago.
Code ships continuously, APIs change, dependencies update, and every merge rewrites part of the story. A general-purpose wiki can't keep pace with that velocity.
The real cost of knowledge silos on engineering productivity
Knowledge silos carry a measurable toll. 45% of developers say silos hurt their productivity three or more times per week, and developers spend over 30 minutes daily searching for answers to technical problems. Across a fifty-person engineering org, that's hundreds of hours each month lost to questions someone already answered.
Those costs compound quietly. Onboarding stretches from days into weeks because new hires can't find context. Senior engineers become human search engines, fielding the same Slack questions repeatedly, each interruption carrying a cognitive switching penalty that outlasts the conversation itself.
The cycle feeds itself: knowledge stays locked in people's heads, those people get interrupted constantly, and nobody has time to document anything. Breaking it requires a system that captures context where it already lives and keeps it current without adding another task to anyone's plate.
How context limits cripple AI agents
Even the most capable AI models operate within finite context windows. When a coding agent works through a multi-step task, tracing a bug across services or generating a migration plan, it burns through tokens fast. Midway through a complex workflow, earlier context gets pushed out. The agent forgets constraints it was given three steps ago and starts producing output that contradicts decisions it already made.
A knowledge layer acts as the agent's persistent memory. Instead of stuffing everything into a single prompt, the agent queries maintained knowledge on demand, pulling in only what's relevant at each step. Context stays accurate, token budgets stay intact, and the agent can reason across long tasks without losing the thread.
What a knowledge layer looks like in practice
Picture your team's typical day. A PR merges that changes how your authentication service handles token refresh. Within minutes, the knowledge layer detects changes and proposes doc updates. No one had to remember which docs existed or where they lived.
That's the practical shape of a knowledge layer:
- It connects to tools already in your stack, such as GitHub, Slack, Linear, and docs, then builds a unified knowledge graph from everything flowing through them
- Documentation updates trigger automatically from pull requests or Slack commands
- Search spans every connected source at once, returning answers instead of links
Setup takes minutes, not sprints. The knowledge graph grows richer as your team works, capturing context from conversations, code reviews, and tickets without anyone changing their workflow.
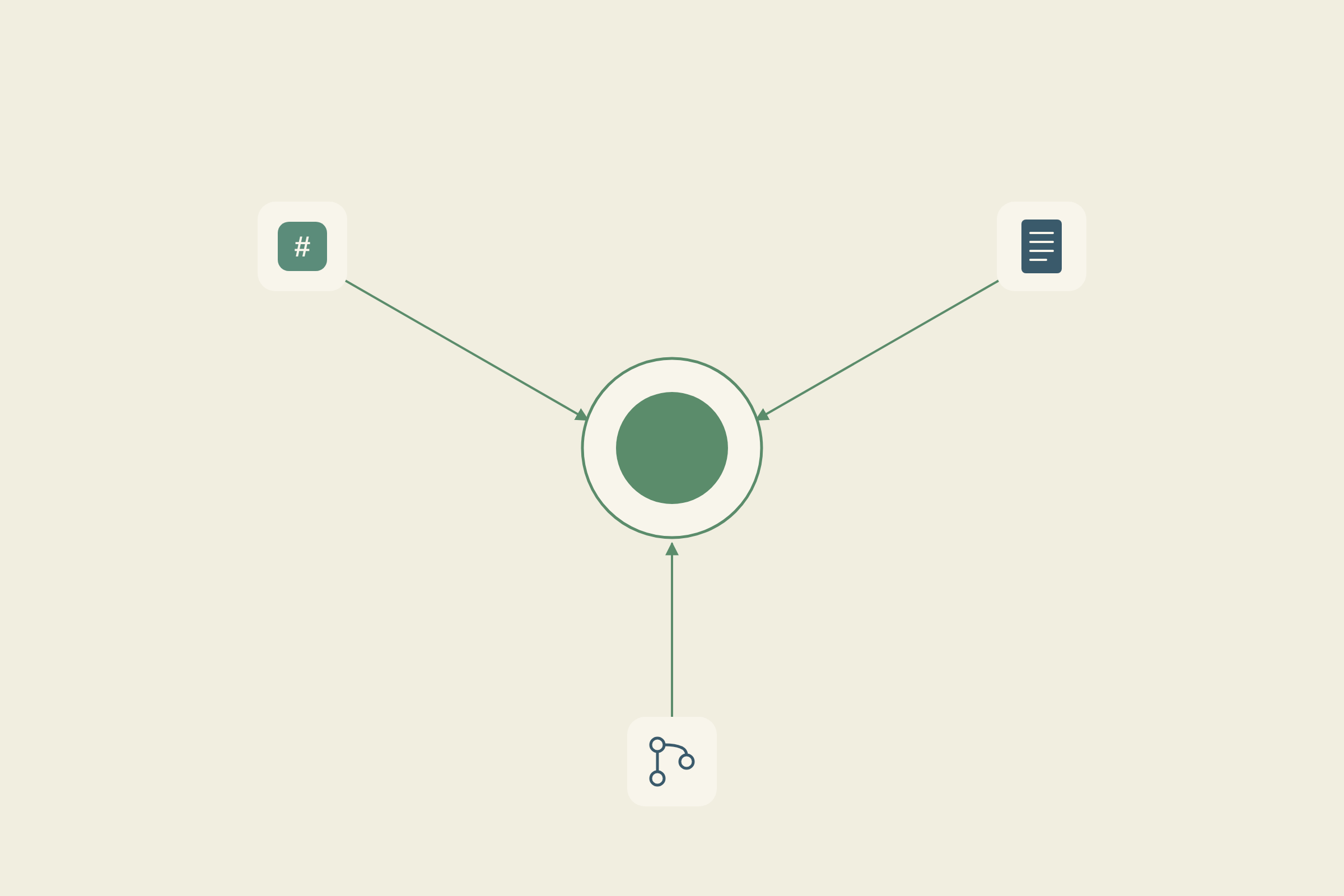
Knowledge graphs vs. vector search: why engineering teams need both
Vector search is great at finding semantically similar content. Ask about "token refresh" and it surfaces docs mentioning authentication flows, session management, and related concepts. But similarity alone can't tell you which services depend on that authentication API or who owns the system you're about to change.
Knowledge graphs fill that gap by mapping relationships between entities: services, teams, APIs, dependencies, and decisions. When these two approaches work together, retrieval understands both meaning and structure. You can ask "what breaks if we deprecate this endpoint?" and get an answer that traces real connections across your codebase, docs, and task history.
Building context sovereignty for your team
Context sovereignty means your team owns its institutional knowledge in a structured, reusable form instead of watching it scatter across one-off prompts, Slack threads, and various AI models.
When context is controlled and well-maintained, it compounds. Every documented decision, every architectural rationale, every onboarding answer becomes raw material that powers new code generation, Q&A systems, agent workflows, and future documentation. The knowledge your team produces today makes tomorrow's work faster.
The teams that treat their context as a managed asset, not an afterthought, are the ones building durable competitive advantages for their engineers and for every AI system those engineers rely on.
Letting knowledge leak into ephemeral prompts means rebuilding context from scratch every time. Owning it means each investment pays forward.
Falconer: a knowledge layer built for engineering teams
Everything described in this post, from self-updating docs to unified search to context sovereignty, is what we built Falconer to do. It connects to your entire stack, then maintains a living knowledge graph that stays current as your code and conversations evolve.
When a PR merges, related docs get flagged and updated. When someone asks a question, unified search returns answers drawn from every connected source. The Falcon AI agent delivers context to coding agents via MCP, so tools like Claude Code and Cursor work with your team's real institutional knowledge instead of guessing.
If you want to see how a knowledge layer works in practice, Falconer is where we'd start.
Final thoughts on engineering knowledge infrastructure
Every hour your team spends searching for answers or re-explaining decisions is an hour not spent building. What a knowledge layer does is capture that institutional context where it already lives and keep it accurate as your code changes. The model isn't your competitive edge, your context is. Try Falconer to see what happens when your team's knowledge works as hard as your team does.
FAQ
How does a knowledge layer stay current when code changes multiple times per day?
A knowledge layer monitors your connected tools like GitHub and Slack, automatically detecting when code changes affect existing documentation and flagging those docs for updates. This happens without manual tracking or remembering which docs reference which code.
What's the difference between a knowledge layer and a company wiki?
A wiki is a static repository that requires manual updates and periodic maintenance, while a knowledge layer actively monitors your tools, keeps documentation synchronized with code changes, and maintains connections between related information across your entire stack.
When should engineering teams consider implementing a knowledge layer?
If your engineers spend over 30 minutes daily searching for answers, your onboarding takes weeks instead of days, or your AI coding tools produce output that ignores team conventions and existing patterns, you need a knowledge layer.
Can a knowledge layer work with the coding agents we already use?
Yes, knowledge layers integrate with coding agents through protocols like MCP, providing them with your team's institutional knowledge so they generate code that matches your conventions, understands service boundaries, and works within your actual constraints.
Why do AI pilots fail without proper context?
AI models can reason powerfully but can't reason about your specific systems, architectural decisions, or team constraints without access to that information. Without a maintained knowledge base feeding institutional understanding to the model, it produces plausible but wrong outputs that ignore how your team actually works.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.