What is a company brain, and why you need one
Your company knows more than you think. The problem is that nobody can find it.
Decisions get made in meetings. Context lives in Slack threads. Code changes in GitHub. Answers to important questions get buried across a dozen tools, and six months later, a new hire asks the same question from scratch because nobody wrote it down. Or someone did write it down, and the answer is wrong now.
That’s a systems problem, not a people problem. The fix is what we call a company brain: a single, always-current knowledge layer that captures what your team knows and keeps it accurate as the underlying work changes.
This guide explains what a company brain actually is, why most attempts to build one fall apart, and how to build one that works.
Key takeaways
- A company brain is a knowledge layer that captures decisions, docs, and context across all your tools, and keeps that information accurate automatically as reality changes.
- Most knowledge tools (Notion, Confluence, Glean) are good at capturing information but don’t update it, so the content goes stale fast.
- A working company brain has to do four things: capture, update, organize, and monitor for drift.
- The “self-updating” part is what separates a company brain from a wiki. Without it, you’re back to manual maintenance, which never holds up at scale.
- AI agents working against stale documentation produce stale outputs. As coding agents take on more of the codebase, the cost of out-of-date context goes up, not down.
What is a company brain?
A company brain is a single knowledge layer where your company’s information lives and stays current. It captures what your team knows, keeps it up to date as the underlying work changes, and makes the result easy for any human or any AI agent to query.
A company brain is not a wiki. It’s not a shared drive. Those are storage. A wiki is a place to write things down; a company brain is a system that maintains what’s been written.
The closest analogy is a librarian, but a tireless one with full read-access to every PR, every Slack thread, and every meeting note. While your team ships, the brain quietly keeps the catalogue accurate.
What a company brain is not
If your knowledge base requires manual upkeep to stay accurate, it’s not really a company brain. It’s a company archive. A few common examples of archives that get mistaken for brains:
- A Notion workspace where nobody updates the pages
- A Confluence site that’s a quarter behind reality
- An AI search tool pointed at stale documentation
- A folder of Google Docs that made sense in 2022
The shared problem in all four is that humans are the only thing keeping them current, and humans are busy.
Why most companies don’t have one
The knowledge exists. It’s scattered, stale, and hard to trust. Three patterns explain most of the failure mode:
Decisions don’t get documented. A Slack thread resolves a real question. The PR merges. The decision never makes it into a doc. Three months later, someone builds against the wrong assumption.
Docs go stale immediately. A runbook gets written on the day a system ships. The system changes six times. The runbook never does. It still looks authoritative, which makes it a trap rather than just a gap.
Nobody maintains it. Every tool on the market is good at capturing knowledge. Almost none of them update it. The moment reality changes, the doc falls behind, and the gap compounds.
This is documentation debt, the knowledge-side cousin of technical debt (a term Ward Cunningham coined in the early 1990s). Cunningham’s metaphor was about software: shortcuts taken now compound into maintenance cost later. Documentation has the same dynamic, and the interest is brutal. A 2021 APQC survey of 982 knowledge workers found that the average respondent loses 2.8 hours a week looking for or requesting information they can’t find. Earlier work from the McKinsey Global Institute put the figure closer to 20 percent of the workweek for interaction workers. Forrester research for Airtable found that large organizations now use an average of 367 software apps and systems, which is part of why the number doesn’t go down.
| What most teams have | What a company brain does | |
|---|---|---|
| Context | Scattered across tools, hard to find | Live and queryable in one place |
| Accuracy | Decays as soon as it’s written | Updates automatically as things change |
| For AI agents | Guessing from outdated info | Working with current, reliable context |
The obvious fixes that don’t work
If you’ve been burned by this before, you’ve probably tried one of two approaches.
The first is to mandate more documentation. Buy Confluence, make documentation an OKR, hire a tech writer. Six months later there’s a graveyard of half-finished pages and a team that resents the process. Documentation debt accrues faster than manual processes can pay it down. The Atlassian retirement of Confluence Server in February 2024 and the Data Center read-only deadline of March 28, 2029 are accelerating this realization for a lot of teams that have been running on the same wiki for a decade.
The second approach is to add AI search on top. Tools like Glean or Notion AI promise smarter retrieval, and the logic seems sound: your knowledge already exists somewhere, you just need a better way to find it. But better retrieval doesn’t fix rot. A smarter search engine pointed at stale docs delivers the wrong answer faster, with more confidence. The problem isn’t finding the knowledge. It’s keeping it true.

What a company brain actually has to do
Whether you’re building one yourself or choosing a tool, a real company brain has to do four things. If it does only some of them, it will break down within a quarter or two.
Capture is the foundation. Every PR, Slack thread, meeting note, and decision needs to be ingested, because if the brain doesn’t see it, the brain can’t learn from it.
Updating is where almost every existing tool falls down. When reality changes (a system gets rebuilt, a process shifts, a team reorganizes), the docs have to change with it. Without automatic updates, you’re back to manual maintenance and the same documentation-debt cycle that started this whole mess.
Organization comes next, because raw capture without structure is just a bigger pile. A good company brain knows which docs are canonical, which are outdated, and which version supersedes which. The technical term for this is a single source of truth, or SSOT: structuring information so every fact is mastered in exactly one authoritative place. A company brain enforces SSOT designations as a property of the system rather than a convention people are supposed to remember.
Drift monitoring is the last piece. The brain should flag when something is wrong: when two docs contradict each other, when a decision was made in Slack but never made it to the spec, when a system changed but the runbook didn’t catch up. Without drift detection, the system has no immune response.
Tools that handle only capture are knowledge bases. The full set of four is what makes the difference between a knowledge base and a company brain.
Why this matters more than it used to
Three years ago, “your wiki is stale” was a productivity annoyance. Now it’s a meaningfully bigger problem, because the consumers of your internal documentation are no longer just humans.
In April 2025, Google CEO Sundar Pichai announced that 75% of new code at Google is AI-generated and approved by engineers, up from 50 percent the prior fall. Most of the rest of the industry is on a similar trajectory. Code is shipping faster than any team can document it.
That has a knock-on effect that most teams haven’t priced in: AI coding agents now read your internal documentation as input. Thoughtworks engineers describe this discipline as “context engineering”, the practice of providing AI agents with the targeted project information they need to produce correct code. The quality of the input determines the quality of the output. An agent reading a runbook that hasn’t been updated since 2024 will confidently produce code that worked in 2024.
A company brain matters more now than it used to because the cost of stale context has gone up. As more of the codebase ships through agents, the lag between what’s true and what’s documented has a price tag attached.
Should you build a company brain yourself?
Some engineering teams hear all this and reach for the obvious move: wire up some integrations, layer a few agents on top, ship it. It sounds reasonable, but the teams that try usually end up reverting to a vendor within a quarter or two.
The integration layer is the easy part. The hard part is maintenance: detecting when reality has drifted from the doc, and updating the artifact without requiring a human in the loop every time something changes. That problem looks like a feature when you start, and like a product when you finish. By the time you’ve solved capture, the rest of the company has shipped two more quarters of work that needs to be ingested, organized, and monitored, and the maintenance burden compounds from there.
Building a company brain in-house is possible, the same way building your own observability stack or your own auth system is possible. The honest question is whether the cost of maintaining it forever is lower than the cost of buying it.
How to build a company brain with Falconer
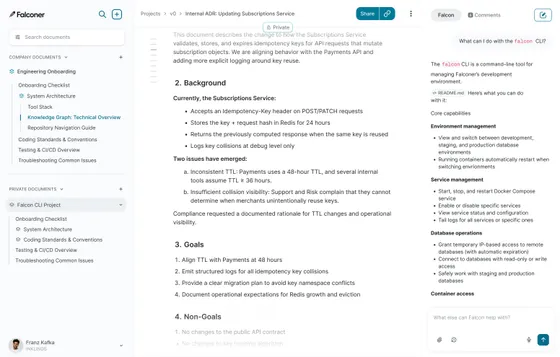
Falconer is a company brain built as a product. It handles capture, updates, organization, and monitoring out of the box, and most teams are running by end of day.
Setup starts with connecting your tools: GitHub, Slack, Linear, Granola, your existing docs. Falconer ingests everything across all of them (PRs, threads, tickets, meeting notes, design specs) and reads what’s there to build a baseline knowledge graph. There’s no manual tagging, no taxonomy you have to design upfront. The system infers structure from the source material.
Once the baseline exists, the next step is to designate canonical sources for each area: architecture decisions, runbooks, onboarding, product specs. When a doc gets marked canonical, Falconer monitors it from that point forward and treats conflicting sources as supplementary context rather than competing truth.
After that, your team ships normally. As PRs merge, threads resolve, and decisions land, Falconer detects which documents are now affected and drafts proposed updates. The relevant document owner reviews and accepts or rejects in seconds, which keeps the human in the loop without making them the bottleneck.
The result is that you can ask your organization anything. Query Falconer about your codebase, a past decision, a runbook, a spec, and the answer comes from current context rather than a six-month-old snapshot. (For a deeper walkthrough of the setup process, see the Falconer documentation.)

How Falconer compares to other tools
Most tools handle one or two of the four jobs. Here’s how they stack up against the company brain definition:
| Tool | Captures | Updates | Organizes | Monitors |
|---|---|---|---|---|
| Notion | Yes | Manual | Partial | No |
| Confluence | Yes | Manual | Partial | No |
| Glean | Retrieval only | No | No | No |
| Falconer | Yes | Automatic | Yes | Yes |
What separates a knowledge base from a company brain is maintenance, not search. Falconer is built around keeping context current rather than around storing it.
Frequently asked questions
What is a company brain? A company brain is a knowledge layer that captures decisions, docs, code, and conversations across a company’s tools, organizes the result into a single queryable structure, and keeps it accurate as the underlying work changes. Unlike a wiki, it updates automatically when reality drifts away from what’s documented.
What’s the difference between a company brain and a knowledge base? A knowledge base stores information. A company brain keeps information current. The difference is maintenance: a knowledge base depends on humans to update it; a company brain detects drift and proposes updates automatically, with humans in the loop only for review.
Why do most company knowledge systems fail? They’re built around retrieval rather than maintenance. Tools like Notion and Confluence capture information well, but neither one updates content when the underlying work changes. The base goes stale the moment it’s written, and adding smarter search on top doesn’t fix the underlying staleness.
Do AI agents need a company brain? Increasingly, yes. As coding agents and other AI tools take on more of the work, they read internal documentation as input. The Thoughtworks team calls this context engineering. Stale docs produce stale outputs, and given that 75 percent of Google’s new code is now AI-generated, the cost of bad context is growing fast.
How long does it take to set up a company brain with Falconer? Most teams are running by end of day. Connect your existing tools (GitHub, Slack, Linear, Notion, Confluence) and Falconer maps your knowledge graph automatically. There’s no manual tagging or taxonomy configuration required.
Do I need to be technical to use a company brain? No. Falconer connects to the tools your team already uses and runs in the background. You interact with it by asking questions in plain language, the same way you’d ask a colleague.
What happens if my team already uses Notion or Confluence? Falconer connects to both. It ingests your existing docs, identifies what’s current versus stale, and maintains them going forward. You don’t have to start from scratch, and for teams facing the Confluence Data Center 2029 deadline, Falconer can serve as the canonical replacement when the migration becomes mandatory.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.