How to build a self-updating company brain (April 2026)
A self-updating company brain is a knowledge system that captures what an organization knows, keeps that knowledge accurate as the underlying work changes, and makes it retrievable when someone (or something) needs it. The "self-updating" part is the hard part. Most teams treat knowledge capture as the problem and stop there. Capture is the easy half. The hard half is knowing what to keep, what to surface, and when to retire something, which is what separates a company brain that compounds in value from a wiki that quietly turns into a graveyard of old pages. This guide walks through the seven principles behind a system that maintains itself, and ends with how Falconer applies each one out of the box.
Key takeaways
- A self-updating company brain is the practices and infrastructure that turn an organization's scattered documents, conversations, and code into reliable, retrievable context that stays accurate as the underlying work changes.
- The unit of knowledge is a passage with provenance, not a whole document. Storing chunks with source attribution, timestamps, and authorship is the foundation everything else rests on.
- Selective storage matters more than complete storage. Redundant or stale content degrades retrieval quality at the claim level, even when it sits in a separate doc.
- A useful company brain distinguishes raw context from episodic records from distilled canonical references, and pushes content up that ladder over time.
- Decay detection (drift, contradiction, coverage gaps, redundancy) is a first-class problem, not a quarterly cleanup task.
- A single source of truth designation works only when it's explicit and enforced. Without that, search results lose trust and people stop relying on the system.
- The "self-updating" half is the difference between a knowledge system that compounds in value and a wiki that decays. It depends on closing the update loop automatically when the underlying work changes.

Why most company knowledge bases fail
A 2021 APQC survey of 982 full-time knowledge workers found that the average respondent spends 2.8 hours a week looking for or requesting information they can't find, on top of broader time losses that pull the productive work down to about 30 hours of a 40-hour week. The number is stubbornly consistent: nearly fifteen years earlier, the McKinsey Global Institute estimated that interaction workers spent close to 20 percent of their workweek on the same task. Forrester's research for Airtable, more recently, found that large organizations now use an average of 367 software apps and systems.
The number of tools went up. The hours lost to searching them did not go down. The underlying model has been the same for two decades: store documents, hope retrieval works, fix things when they break. A self-updating company brain is built on a different model.
Principle 1: Treat the chunk as the unit of knowledge, not the document
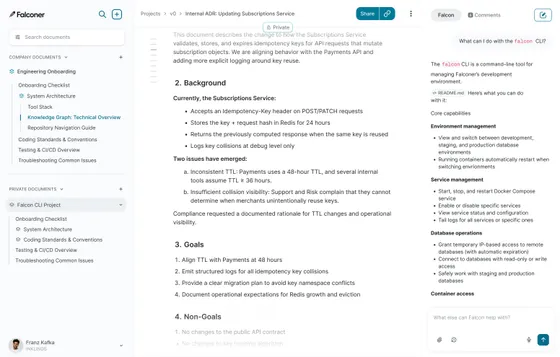
The instinct is to store documents. Documents are containers, though, and the actual unit of useful knowledge is smaller: a passage of content with the context attached to it. What it says, where it came from, when it was written, who wrote it.
When a company brain organizes around atomic passages instead of whole documents, three things change. Search returns the relevant section instead of forcing the reader to skim a 4,000-word page. Contradictions surface at the claim level, where they can be resolved, instead of at the document level, where they hide. And content from different sources (a design doc, a code comment, a Slack thread) can be connected meaningfully because the system is comparing claims, not files.
This is also the foundation of every modern retrieval-augmented generation system. The seminal RAG paper from Lewis and colleagues at FAIR identified provenance and chunking as two of the open research problems in giving language models access to factual knowledge. Five years on, the engineering work has moved a long way; the underlying requirement has not. Every retrievable unit needs to know where it came from. Wikis have needed this all along, even before any AI was reading them.
Principle 2: Build a vocabulary layer over your content
Alongside the content, every organization needs a layer of named concepts. Product names, core systems, internal processes, team names, customer accounts. These become stable anchors that connect knowledge across sources.
When the same concept appears in a design doc, a pull request, and a Slack thread, a good knowledge system links all three to the same concept node. That's how cross-source context works. Not by merging everything into one place, which collapses the useful structure, but by understanding that all three pieces are talking about the same thing.
The technical literature calls this entity grounding. Anthropic's research on contextual retrieval found that adding chunk-specific explanatory context before embedding reduced retrieval failure rates by 35 percent, and combining contextual embeddings with contextual BM25 reduced them by 49 percent. Industry replications on financial documents have found similar or larger gains. The mechanism behind those results is straightforward: a chunk that knows what entity it's describing retrieves better than a chunk that doesn't.
Principle 3: Don't store everything
This is the counterintuitive one, and it's the most important principle on the list.
Every redundant, low-signal piece of content stored in a knowledge base degrades retrieval quality. Every stale doc that contradicts a newer one creates noise. Every duplicate of something already known dilutes results. A knowledge base that ingests indiscriminately gets worse the more it grows.
A healthy system filters on the way in. Before storing something, the question to ask is whether it adds something the system doesn't already know, whether it's specific enough to be useful in a future search, and whether it will still be accurate in six months or actively misleading. If the answer to any of those is no, the content should either be skipped or flagged for review on a schedule.
A noisy knowledge base costs more than the storage it occupies. The real cost is that people stop trusting the search results, and once trust is gone it's hard to recover.
Principle 4: Use a knowledge maturity model
Not all knowledge deserves the same treatment, and a useful framework distinguishes three tiers:
| Tier | What it is | Examples | Shelf life | | --- | --- | --- | --- | | Raw context | Recent conversations and unstructured signal | Slack threads, meeting transcripts, comments on a PR | Days to weeks | | Episodic knowledge | Specific records tied to a moment in time | Design docs, RFCs, code functions, decision records | Months to years | | Distilled knowledge | Patterns extracted and consolidated from multiple sources | Canonical references like "our auth tokens expire after 24 hours" | Long-lived; revisited on change |
The bulk of what most teams store sits in the episodic tier. The goal over time is to push content upward where the patterns justify it. Raw context gets captured into episodic docs when it matters. Recurring episodic content gets distilled into canonical references. The more distilled the system, the faster people get answers, and the less the system depends on any one person remembering where something was written down.
Principle 5: Designate a single source of truth for contested topics
Every organization has topics where multiple documents say slightly different things. Deleting the duplicates rarely works, because each one was written for a reason and someone keeps re-creating them. The better move is to designate one source as authoritative and make that designation visible in the system itself.
In information science, the term for this is single source of truth, or SSOT. It refers to the practice of structuring information models such that every data element is mastered or edited in only one place, providing data normalization to a canonical form. When sources conflict, the SSOT wins. Everything else is supplementary context.
Accuracy is part of the benefit, but the bigger return is confidence. When people know which document is authoritative, they stop second-guessing search results and start trusting the system. Trust is the metric most knowledge bases never measure and never recover once it's lost.
Principle 6: Treat decay as a first-class problem
Knowledge rots. Code changes. Processes evolve. Decisions get revisited and reversed. A doc that was correct six months ago can be actively wrong today, and most teams handle this reactively: someone notices a doc is wrong, files it, and a quarter later someone gets around to fixing it. That works at small scale. It breaks down past about fifty engineers.
A working system builds decay detection in. The signals worth watching:
- Code drift. Documentation that describes behavior the codebase no longer matches.
- Contradiction. Two sources that now say opposite things, where they used to agree.
- Coverage gaps. Topics the team discusses frequently in Slack with no corresponding documentation.
- Redundancy. Multiple docs saying the same thing that should be consolidated into one.
None of these need immediate fixes. They need to be surfaced. Surfacing them is the part the system can do; deciding what to fix is the part that needs a human.

Principle 7: Close the loop on updates (the self-updating part)
The last failure mode is the one that quietly destroys the most value. Knowledge gets updated in one place but not the others.
A decision gets made in a meeting. Someone updates the Slack thread. Nobody updates the doc. Six months later, a new hire reads the doc and acts on stale information. By the time the mistake gets caught, it's already cost something.
A self-updating company brain makes this loop explicit. A change happens (code merges, a decision lands, a process shifts) and the system identifies which documents are semantically affected. Updates get drafted and routed to the document owner. The owner reviews and accepts or rejects in seconds.
The human stays in the loop. The system does the work of figuring out what needs to catch up. Without that, updates depend entirely on people remembering to update things in their off-cycle moments, which competes with whatever else is on their plate that week, and usually loses.
What a self-updating company brain produces
A company brain built on these seven principles does something most wikis never manage: it stays useful as it grows. The teams that get this right report faster onboarding, fewer repeated questions in Slack, and better output from the AI tools that sit on top of the corpus, because the context those tools retrieve is current and well-grounded rather than just voluminous.
The shift this represents is real. Atlassian ended support for Confluence Server on February 15, 2024, and Confluence Data Center installations transition to a read-only state on March 28, 2029. The static company wiki, as a category, has a defined sunset. What replaces it has to handle decay, provenance, and structure as defaults, not as user-driven workflows that nobody has time for.
How Falconer maps to each principle
Building a self-updating company brain from scratch is possible. It's also a serious infrastructure project, and most teams don't have the engineering time to make it the side quest of their year. Falconer is a company brain built around these principles as the default behavior. You connect your existing tools and the system starts working, without any of the custom-agent setup or taxonomy design that usually comes with this kind of infrastructure.
| Principle | What Falconer does | | --- | --- | | Atomic units with provenance | Ingests content from docs, code, Slack, meetings, and connected tools, breaking it into chunks with full source attribution. Every answer cites where it came from. | | Vocabulary layer | Builds a knowledge graph of named entities (people, systems, products, decisions) and links every piece of content back to the concepts it discusses. | | Selective storage | Built-in ingestion intelligence skips content that hasn't meaningfully changed and avoids re-processing material that duplicates what's already known. | | Single source of truth | Documents carry authority designations. SSOT documents are canonical; conflicting sources defer to them. | | Decay detection | Monitors for contradictions, coverage gaps, staleness, and redundancy. Surfaces signals on demand or when sources change — ask Falcon to audit any doc or your full knowledge base at any time. | | Update loops | When a GitHub PR merges, Falconer identifies semantically affected documents and drafts proposed updates for the owner to review. |
Most teams are running within a day. Connect a GitHub repo, a Slack workspace, or an existing Notion or Confluence workspace, and the company brain starts building itself automatically.
The compounding part is the point. A self-updating company brain gets more useful the longer it runs, because the graph grows richer, the distilled tier gets more precise, and the decay signals get caught earlier. Building this from first principles is possible. Letting the infrastructure handle it is faster.
FAQ
What is a self-updating company brain? A self-updating company brain is a knowledge system that captures what an organization knows across docs, code, chat, and meetings, and keeps that knowledge accurate as the underlying work changes, without depending on people to manually update every doc when something shifts. The "self-updating" part is what separates it from a static wiki: when a code change, decision, or process update lands, the system identifies which documents are affected and routes proposed updates to the right owner.
How is a company brain different from a wiki or documentation tool? A wiki is a place to write things down. A company brain is a layer that handles capture, retrieval, decay detection, and update routing across all the places knowledge already lives (docs, code, chat, meetings) without requiring everything to be migrated into a single tool.
What does "self-updating" actually mean in practice? It means the system watches for changes in the underlying sources (a merged PR, a new decision in a meeting transcript, a process change in Slack) and automatically identifies which documentation is now stale or contradicted. It then drafts proposed updates and routes them to the document owner for review. The owner stays in control; the system removes the burden of remembering what to update.
What's the difference between a single source of truth and just having one wiki? A single source of truth is a designation, not a tool. SSOT architecture refers to structuring information models so every data element is mastered in only one place. One wiki with five contradictory pages is not an SSOT. One designated authoritative doc, with everything else linking to it, is.
Why does chunking matter for AI retrieval inside a company brain? Most AI tools that read company knowledge use retrieval-augmented generation, which works by breaking documents into smaller passages and matching them to user queries by semantic similarity. Better chunking, with provenance and entity context attached, leads to better retrieval. Anthropic's research showed contextual retrieval reduced top-20-chunk retrieval failure by 49 percent versus standard chunking when combined with BM25, and academic work since has compared late-chunking and contextual-retrieval approaches in more depth.
How often should the company brain get audited for staleness? As often as makes sense for your team's pace — on demand, after major releases, or whenever you suspect drift. Manual quarterly audits don't scale past about fifty engineers. Detection is the part a system can automate; deciding what to act on still needs a person who understands the work.
Does Falconer replace Confluence or Notion? It can, but it doesn't have to. Falconer connects to existing wikis and treats them as one source among many. For teams with healthy Confluence or Notion deployments, Falconer adds the retrieval, decay detection, and update routing on top. For teams looking to migrate off (particularly given the Confluence Data Center read-only deadline of March 28, 2029) Falconer can serve as the canonical replacement.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.